Chatgpt训练过程
Chat-GPT 训练过程
Pretrained (self superwised learning) 预训练 -> supervised learning (监督学习 - finetune) -> reenforced human feedback (强化学习)
训练流程
第一步:文字接龙

GPT(Generative Pre-trained Transformer)是一个会文字接龙的模型,给他一段文本,他会预测下一个字是什么。
{kind=link}

训练一个文字接龙的模型是不需要人工标注的文本的,只需要在网上收集大量的文字,就可以学文字接龙这件事情。

GPT真实的输出是一个概率分布,“你好”的输入,可能跟“高”、“美”、“吗”等等词,每一次的输出都是不同的,出现的概率也不一样。

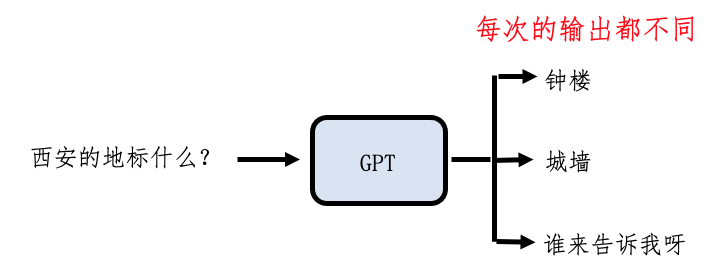
文字接龙已经可以用来回答问题了,但是…
{kind=link}

GPT输出的是一个概率分布,后面可以接各式各样的句子,很多并不是我们想要的。 那我们如何引导GPT产生有用的输出呢?
第二步:人类老师引导文字接龙方向
找人来思考想问GPT的问题,并人工提供正确答案。
西安的地标是什么? --> 钟楼
如何学习深度学习? --> 需要先知道基本概念…
请把这句话做翻译…
让原始的GPT模型在这部分质量较高的数据集上学习,多看一些有益的句子,期待他能产生出有用的输出。这里不需要穷尽所有问题,只需要告诉GPT人类的偏好。
第三步:模仿人类老师的喜好
训练一个模仿老师的模型,学习人类老师评分高低的标准。

如果人类提交的是“钟楼”这个答案好于“谁来告诉我呀”,那么Teacher Model给“钟楼”这个的打分就要比“谁来告诉我呀”的打分高。
第四步:用强化学习向模拟老师学习
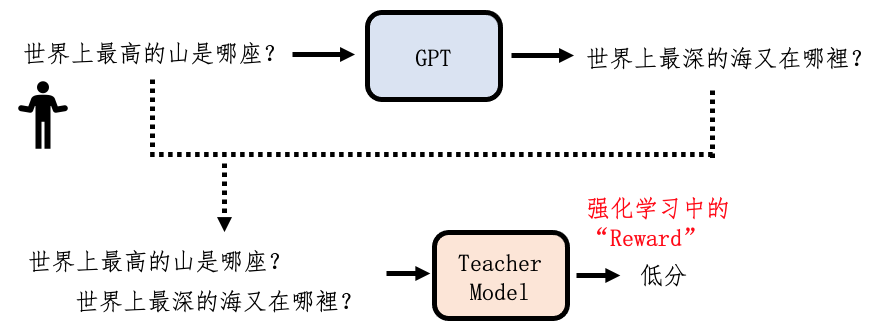
把“接龙模型GPT”和“老师模型Teacher Model”组合起来使用。
{kind=link}

Teacher Model通过前面的学习已经学到,如果答案是一个问句,它不是一个好的答案,给予低分。这个Teacher Model输出的低分就是强化学习的奖励Reward,强化学习通过调整参数,得到最大的Reward
经过强化学习以后,GPT就变成了ChatGPT,能够输出我们想要的答案了。
总结:整个过程就是教GPT从“想说什么就说什么”到“说人类想要他说的”。
Last updated