chatgpt工程实现
第二层:工程实现
重点讲解Instruct GPT的论文,《Training language models to follow instructions with human feedback》(训练语言模型是他能够服从人类的指示)。68页的论文主要内容在讲工程实现,包括怎么挑选合适的标注人员,各个模型都是如何准备训练数据的,甚至还给了很多标注表格的模板和训练样本范例。
大型语言模型中的一致性问题通常表现为:
提供无效帮助:没有遵循用户的明确指示。
内容胡编乱造:虚构不存在或错误事实的模型。
缺乏可解释性:人们很难理解模型是如何得出特定决策或预测的。
内容偏见有害:一个基于有偏见、有害数据训练的语言模型可能会在其输出中出现这种情况,即使它没有明确指示这样做

{kind=link}
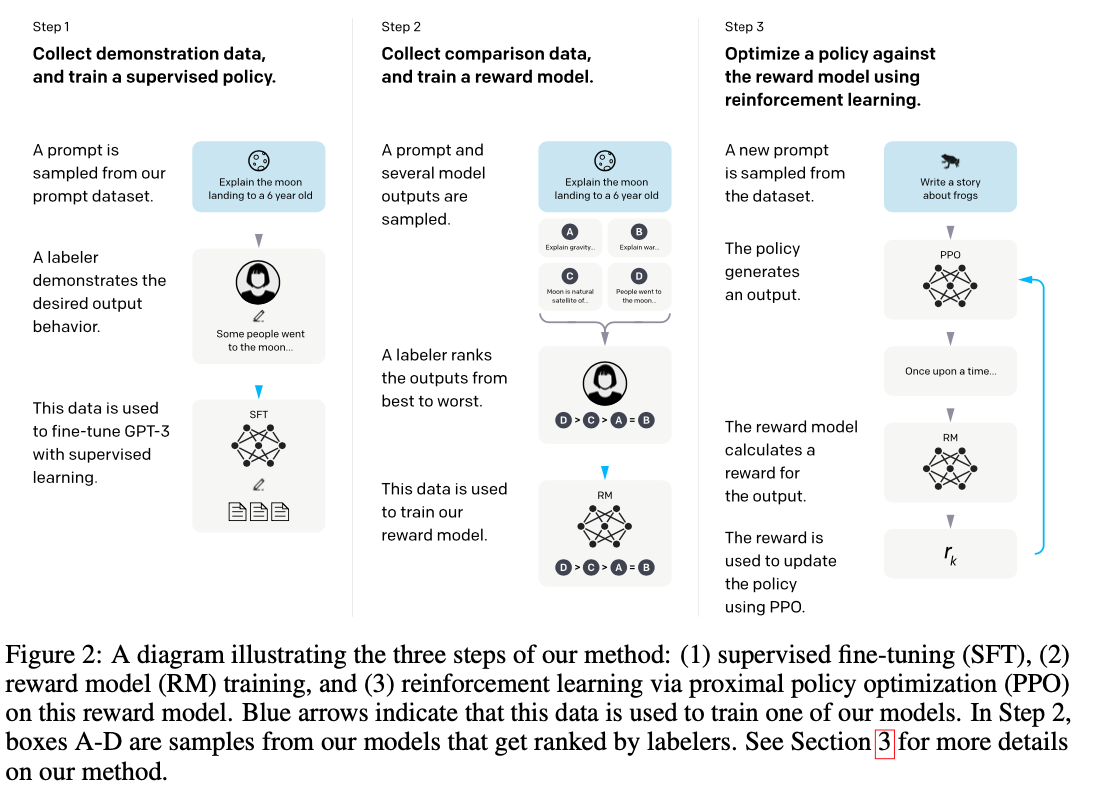
InstructGPT/ChatGPT的提出了一种利用人类反馈来解决这一问题的方案,方法总体上可以分成3步:
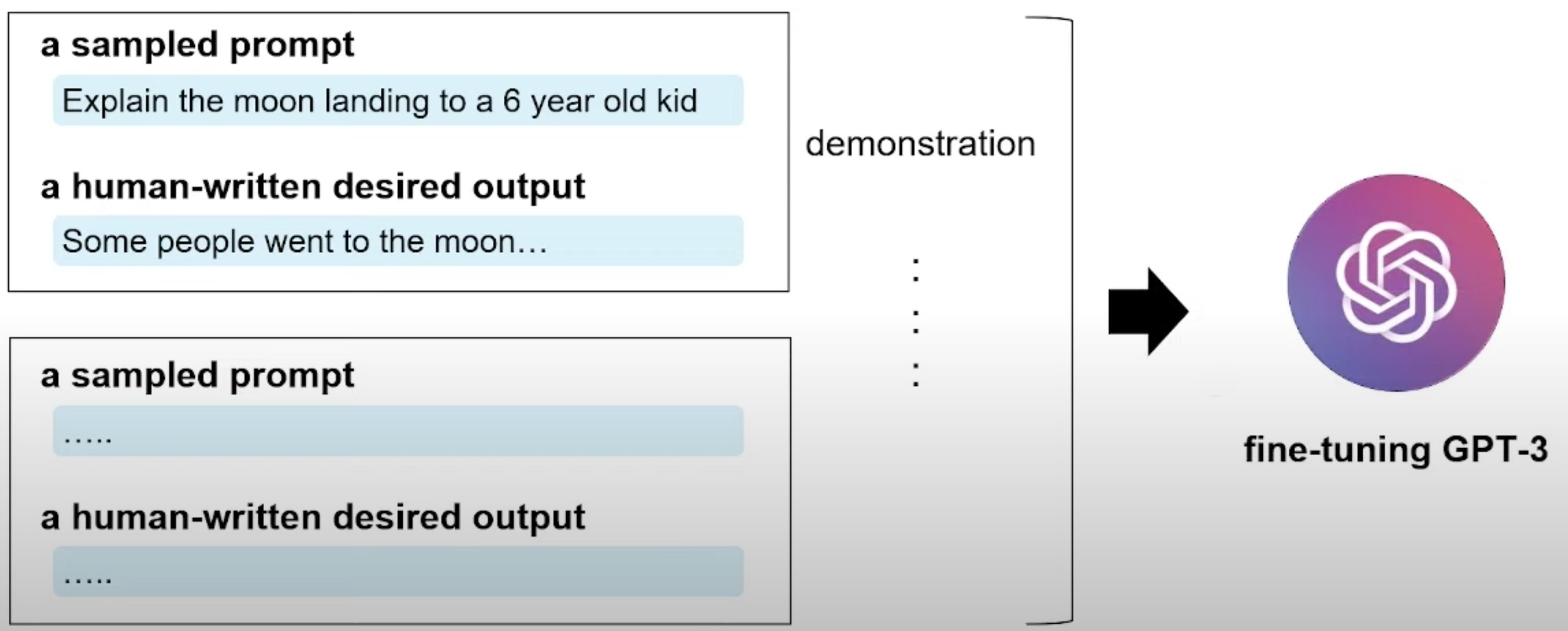
根据采集的SFT数据集对GPT-3进行有监督的微调(Supervised FineTune,SFT);
收集人工标注的对比数据,训练奖励模型(Reword Model,RM);
使用RM作为强化学习的优化目标,利用PPO算法微调SFT模型。
2.1 数据来源
训练数据有两个来源:
由我们的标注人员编写的Prompt数据集
提交给早期 InstructGPT模型版本API的Prompt数据集
标记人员
OpenAI通过一系列的筛选,找到了40个对不同人口群体的偏好敏感并且善于识别可能有害的输出的全职标记人员。整个过程中,OpenAI的研发人员跟这些标记人员紧密合作,给他们进行了培训,并对他们是否能够代表大众的偏好进行了评测。
标记人员的工作是根据内容自己编写prompt,并且要求编写的Prompt满足下面三点:
简单任务:标记人员给出任意简单的任务,同时要确保任务的多样性;
Few-shot任务:标注人员写出一个指示,同时写出其各种不同说法。
用户相关的:从接口中获取用例,然后让标记人员根据这些用例编写prompt

{kind=link}
40名外包员工来自美国和东南亚,分布比较集中且人数较少, InstructGPT/ChatGPT的目标是训练一个价值观正确的预训练模型,它的价值观是由这40个外包员工的价值观组合而成。而这个比较窄的分布可能会生成一些其他地区比较在意的歧视,偏见问题。
API用户
OpenAI训练了一个早期版本的InstructGPT,开放给了一部分用户,根据他们提问信息构造样本,对数据集做了如下操作:
删除了一些重复的、包含个人信息的prompt;
每个用户只取200条prompt;
按照用户ID划分训练集、验证集和测试集,避免类似问题同时出现在训练集和验证集

{kind=link}
prompt种类共有9种,而且绝大多数是生成类任务,可能会导致模型有覆盖不到的任务类型;
2.2 训练数据
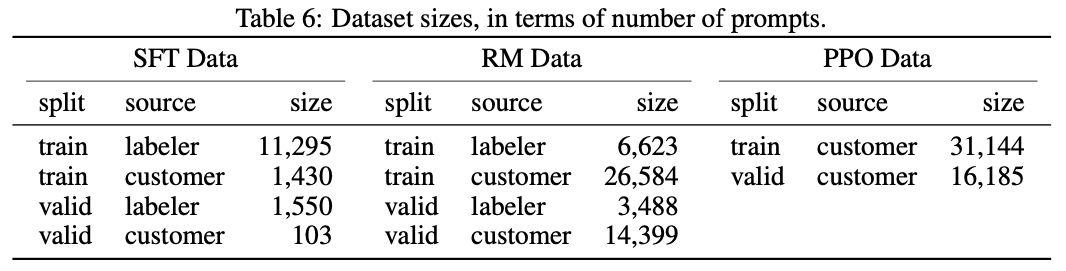
基于上面的数据集,生成了三份不同的训练数据集:
SFT dataset
由标记人员编写prompt对应的回答
13k
Supervised FineTune(SFT)
RM dataset
由标记人员对gpt产生的答案进行质量排序
33k
Reword Model(RM)
PPO dataset
不需要人工参与,gpt产生结果,RM进行打分
31k
Reinforcement learning (RL)

{kind=link}
数据中96%以上是英文,其它20个语种例如中文,法语,西班牙语等加起来不到4%,这可能导致InstructGPT/ChatGPT能进行其它语种的生成时,效果应该远不如英文;
2.3 模型微调Supervised fine-tuning(SFT

{kind=link}
低层的网络主要学习图像的边缘或色斑,中层的网络主要学习物体的局部和纹理,高层的网络识别抽象的语义。
由上面的案例可知,我们可以把一个神经网络分成两块:1)低层的网络进行特征抽取,将原始信息变成容易被后面任务使用的特征;2)输出层的网络进行具体任务的预测。输出层因为涉及到具体任务没办法在不同任务中复用,但是低层的网络是具有通用型的,可以应用到其他任务上

{kind=link}
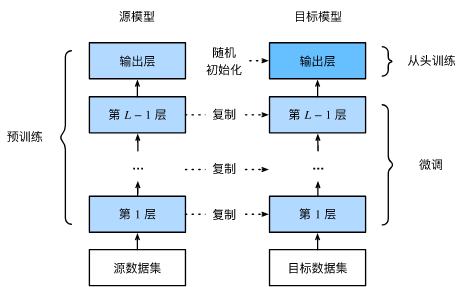
微调由以下4步构成:
在源数据集上预训练一个神经网络模型,即源模型。
创建一个新的神经网络模型,即目标模型。它复制了源模型上除了输出层外的所有模型设计及其参数。我们假设这些模型参数包含了源数据集上学习到的知识,且这些知识同样适用于目标数据集。我们还假设源模型的输出层与源数据集的标签紧密相关,因此在目标模型中不予采用。
为目标模型添加一个输出大小为目标数据集类别个数的输出层,并随机初始化该层的模型参数。
在目标数据集上训练目标模型。我们将从头训练输出层,而其余层的参数都是基于源模型的参数微调得到的

{kind=link}
这里的SFT就是基于训练好的GPT-3模型进行的微调,在数据集上面进行了16个epoch的训练,数据量比较小,模型比较大,一个epoch以后就过拟合了,但是论文里面说这个没关系,因为他不是直接拿出去用,而是用来初始化后面的模型。
2.4 训练奖励模型Reward modeling(RM)
一个Response不能给具体的打分值,只能说一个Response比另一个Response更好或者差不多,所以训练奖励模型的数据是一个标注人员根据生成结果排序的形式,它可以看做一个回归模型

{kind=link}
奖励模型使用的是PairWise的训练方法,PairWise的基本思路是对样本进行两两比较,构建偏序文档对,从比较中学习顺序。PairWise就是希望通过正确估计一对文档的顺序,而得到整体的正确顺序,比如一个正确的排序为:“A>B>C”,PairWise通过学习两两之间的关系“A>B”,“B>C”和“A>C”来推断“A>B>C”

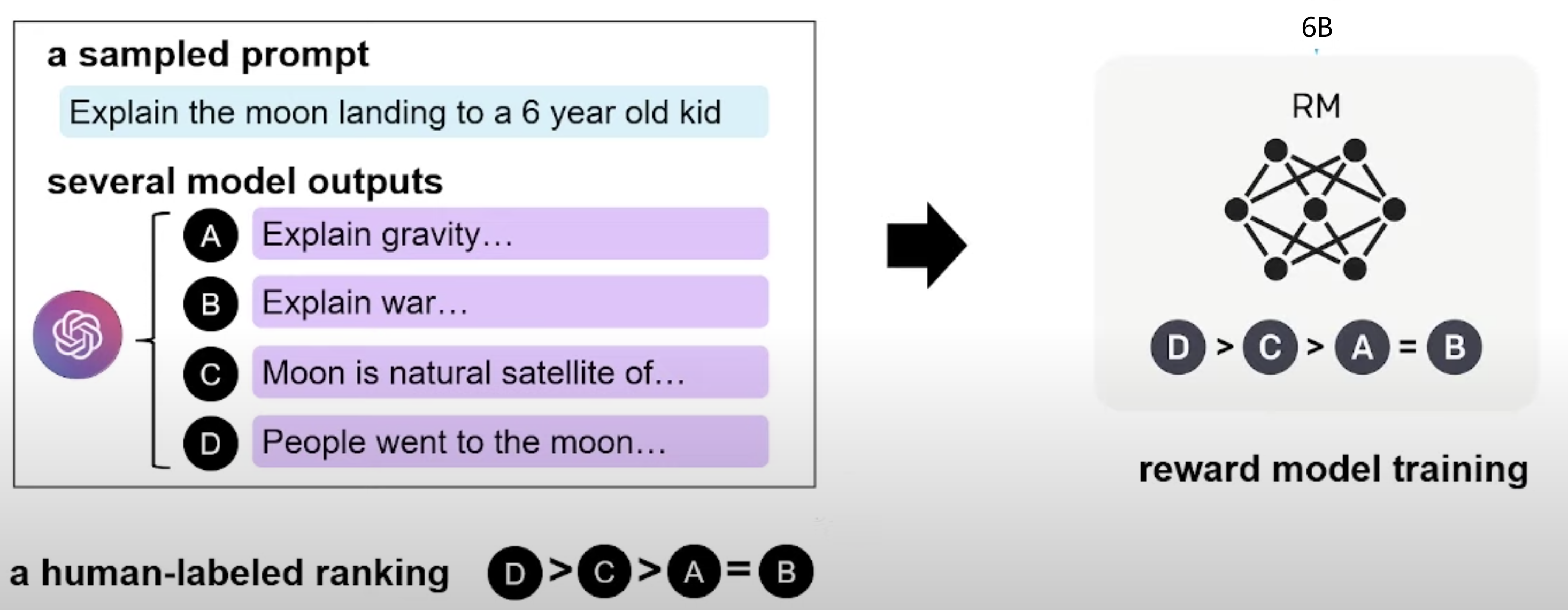{kind=link}
奖励模型的结构是将SFT训练后的模型的最后的嵌入层去掉后的模型。它的输入是prompt和Reponse,输出是奖励值。GPT-3最大的模型时175B的,但是发现这种规模的模型训练不稳定,最后才用了6B的版本。
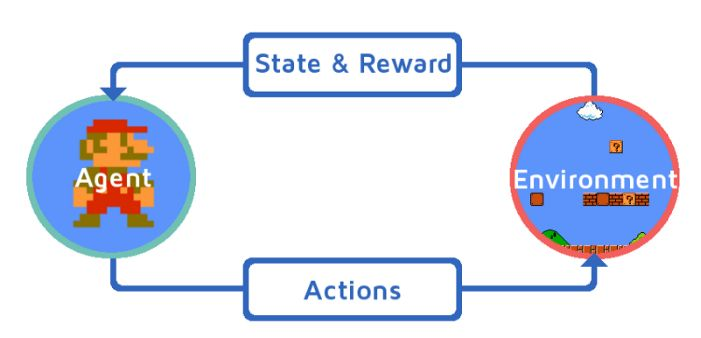
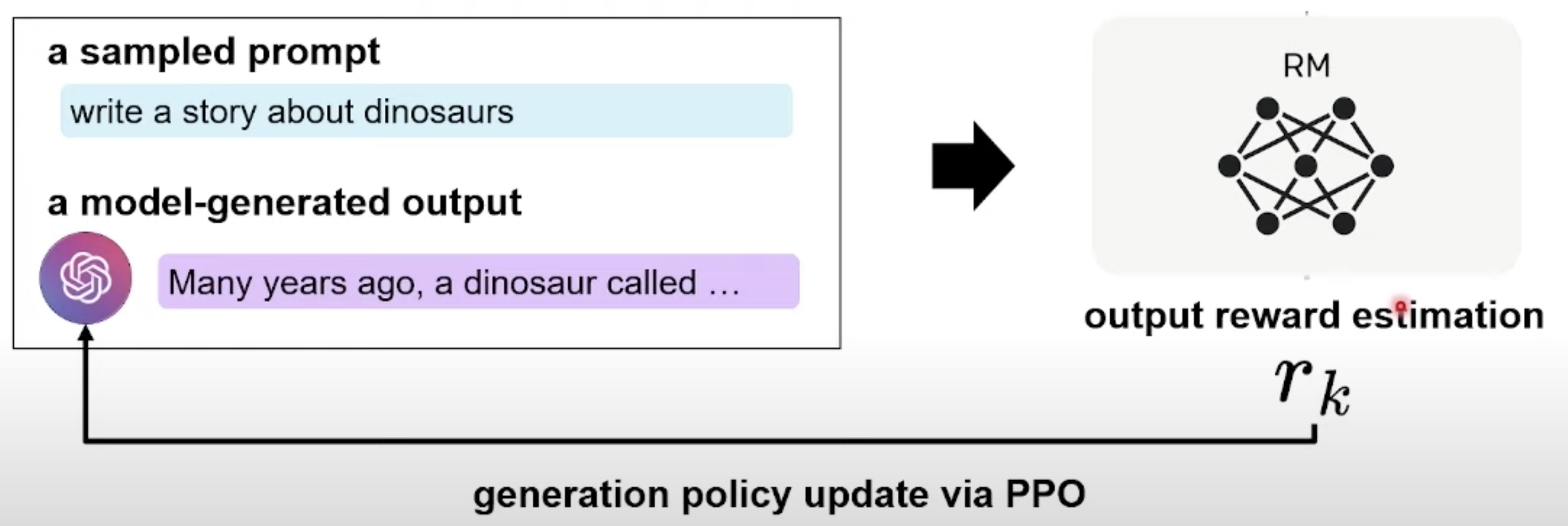
2.5 强化学习Reinforcement learning(RL

{kind=link}
强化学习(Reinforcement learning,RL)讨论的问题是一个智能体(agent)怎么在一个复杂不确定的 环境(environment) 里面去极大化它能获得的奖励。通过感知所处环境的 状态(state) 对 动作(action) 的反应(reward),来指导更好的动作,从而获得最大的收益(return),这被称为在交互中学习,这样的学习方法就被称作强化学习

{kind=link}
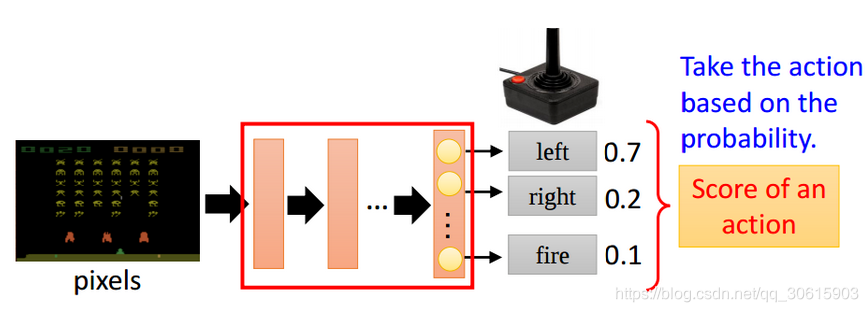
PPO(Proximal Policy Optimization)近端策略优化算法,是一种典型的强化学习算法。它通过观测信息选出一个行为直接进行反向传播,当然出人意料的是他并没有误差,而是利用reward奖励直接对选择行为的可能性进行增强和减弱,好的行为会被增加下一次被选中的概率,不好的行为会被减弱下次被选中的概率

{kind=link}
这里我们随机取一个用户的prompt,然后使用SFT模型生成一个response,使用奖励模型对当前的prompt-response对打分作为Reward。
2.6 结论

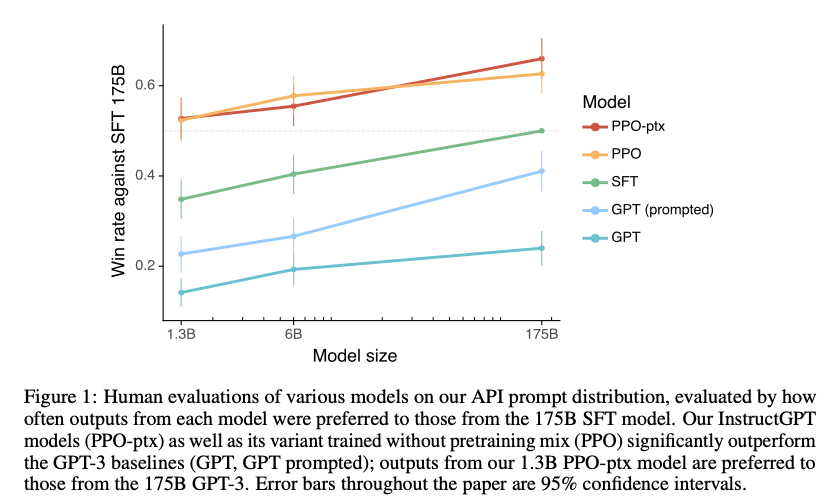{kind=link}
该模型基于三个标准进行评估:
帮助性:判断模型遵循用户指示以及推断指示的能力。
真实性:判断模型在封闭领域任务中有产生虚构事实的倾向。
无害性:标注者评估模型的输出是否适当、是否包含歧视性内容。
跟SFT 175B的模型对比效果,所以我们可以看到SFT 175B的胜率是0.5。
在对我们的prompt进行人工评估过程中,1.3B个参数的InstructGPT模型的输出优于 175B的GPT-3模型的输出,尽管参数少100倍。此外,InstructGPT模型显示了真实性的提高和有毒输出生成的减少,同时在公共数据集上的性能下降却很小。尽管InstructGPT 仍然会犯一些简单的错误,但我们的结果表明,根据人类反馈进行微调是使语言模型与人类意图保持一致的一个有前途的方向。
Last updated