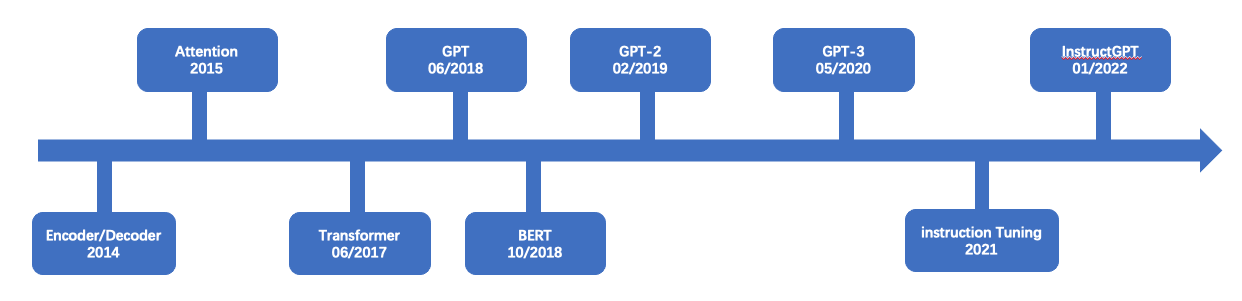
Chatgpt发展过程
Chatgpt
第三层:发展脉络
任何模型的突破和成功,都不是一蹴而就的,是不断的学习前人的经验和结论,自己一步一步走出来的,这个需要的是厚积薄发。ChatGPT也是一样,要真正理解它,就需要看它之前的工作,从发展脉络的角度去看问题

{kind=link}
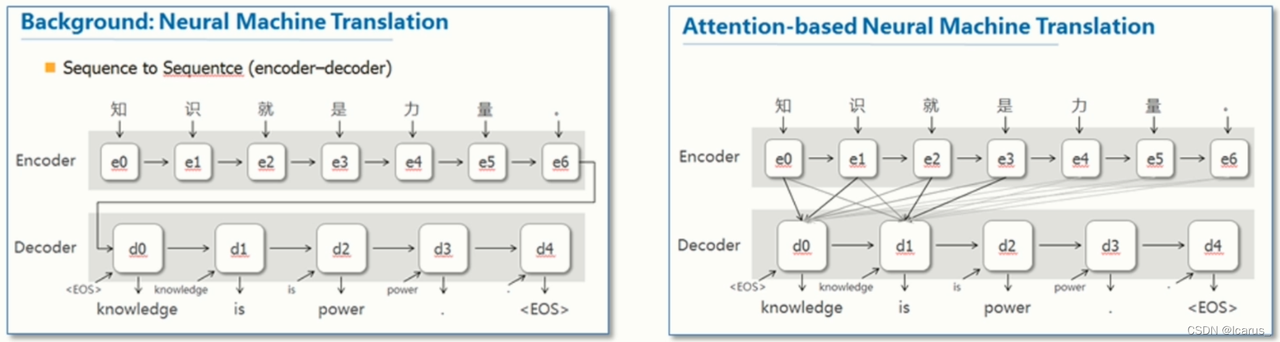
3.1 Encoder-Decoder
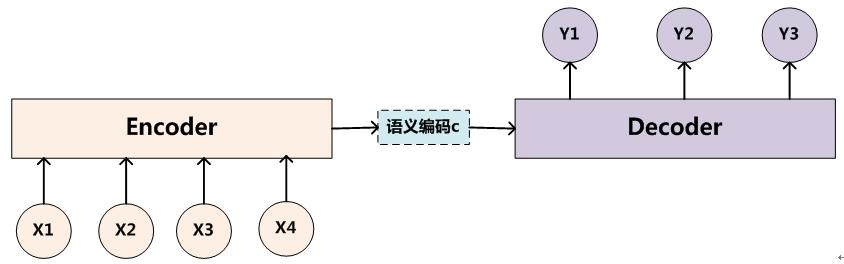
Cho在2014年的《Learning Phrase Representations using RNN Encoder–Decoder for Statistical Machine Translation》中提出了Encoder–Decoder结构,它由两个RNN组成,另外本文还提出了GRU的门结构,相比LSTM更加简洁,而且效果不输LSTM

{kind=link}
生成目标句子单词的过程成了下面的形式,其中f1是Decoder的非线性变换函数:
Y1=f1(C)
Y2=f1(C,Y1)
Y3=f1(C,Y1,Y2)
Encoder和Decoder部分可以是任意的文字、语音、图像和视频数据,模型可以采用CNN,RNN,BiRNN、LSTM、GRU等等,所以基于Encoder-Decoder的结构,我们可以设计出各种各样的应用算法。比如:1)文字-文字:机器翻译,对话机器人,文章摘要,代码补全; 2) 音频-文字:语音识别; 3) 图片-文字:图像描述生成
Encoder-Decoder的出现,对于很多领域的影响是非常深远的,比如机器翻译的任务,再也不需要做词性分析、词典查询、语序调整和隐马尔可夫模型等等方案,几乎都是基于Encoder-Decoder框架的神经网络方案。
3.2 Attention机制
Attention机制最早在视觉领域提出,2014年Google Mind发表了《Recurrent Models of Visual Attention》,使Attention机制流行起来,这篇论文采用了RNN模型,并加入了Attention机制来进行图像的分类。
2015年,Bahdanau等人在论文《Neural Machine Translation by Jointly Learning to Align and Translate》中,将attention机制首次应用在nlp领域,其采用Seq2Seq+Attention模型来进行机器翻译,并且得到了效果的提升

{kind=link}
语义编码C是由句子Source的每个单词经过Encoder编码产生的,这意味着不论是生成哪个单词,其实句子Source中任意单词对生成某个目标单词来说影响力都是相同的,这是为何说这个模型没有体现出注意力的缘由。这类似于人类看到眼前的画面,但是眼中却没有注意焦点一样。
我们拿机器翻译来解释一下注意力在Encoder-Decoder模型中的作用就更好理解了,比如输入的是英文句子:Tom chase Jerry,Encoder-Decoder框架逐步生成中文单词:“汤姆”,“追逐”,“杰瑞”。
在翻译“杰瑞”这个中文单词的时候,没有注意力的模型里面的每个英文单词对于翻译目标单词“杰瑞”贡献是相同的,很明显这里不太合理,显然“Jerry”对于翻译成“杰瑞”更重要,但是没有注意力的模型是无法体现这一点的。
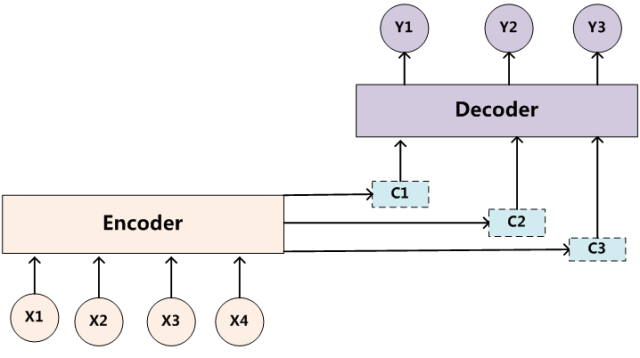
目标句子中的每个单词都应该学会其对应的源语句子中单词的注意力分配概率信息。这意味着在生成每个单词yi的时候,原先都是相同的中间语义表示C会被替换成根据当前生成单词而不断变化的Ci。理解Attention模型的关键就是这里,即由固定的中间语义表示C换成了根据当前输出单词来调整成加入注意力模型的变化的Ci。增加了注意力模型的Encoder-Decoder框架理解起来如图所示

{kind=link}
即生成目标句子单词的过程成了下面的形式:
Y1=f1(C1)
Y2=f1(C2,Y1)
Y3=f1(C3,Y1,Y2)

{kind=link}
Attention机制由来已久,真正让其大放异彩的,是后来Google的一篇文章《Attention is All You Need》。
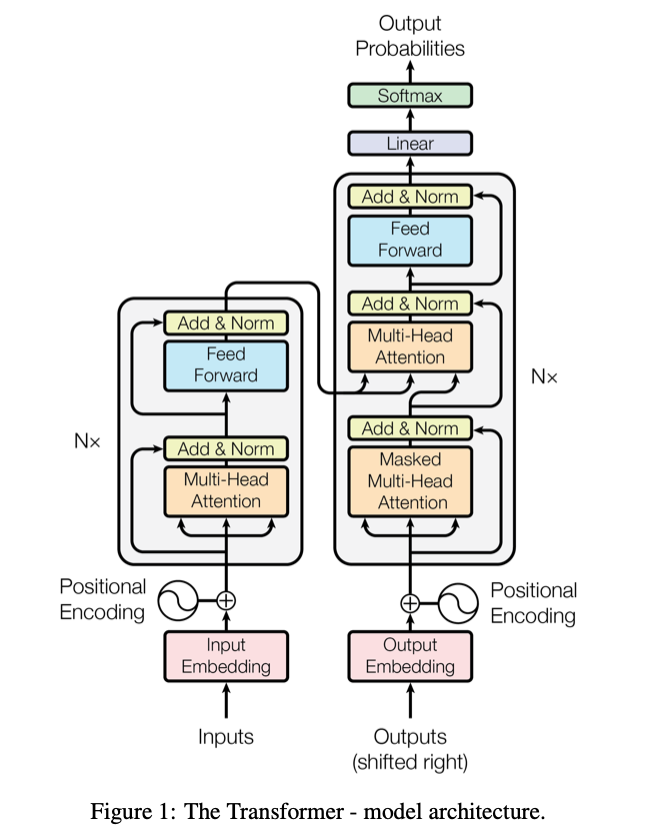
3.3 Transformer
2017年,Google机器翻译团队发表的《Attention is All You Need》中,提出了他们的Transformer架构,Transformer基于经典的机器翻译Seq2Seq框架,完全抛弃了RNN和CNN等网络结构,而仅仅采用Attention机制来进行机器翻译任务,在WMT 2014的数据集上取得了很好的成绩

{kind=link}
编码器 编码器由N=6个相同的layer组成,layer指的就是上图左侧的单元,最左边有个“Nx”,这里是x6个。每个Layer由两个子层(Sub-Layer)组成,第一个子层是Multi-head Self-attention Mechanism,第二个子层比较简单,是Fully Connected Feed-Forward Network。其中每个子层都加了残差连接(Residual Connection)和层归一化(Layer Normalisation),因此可以将子层的输出表示为: LayerNorm (x+SubLayer(x))
解码器 解码器同样由N=6个相同layer组成,因为编码器是并行计算一次性将结果直接输出,而解码器是一个词一个词输入,所以解码器除了每个编码器层中的两个子层之外,还插入第三子层,其对编码器堆栈的输出执行multi-head attention。每个子层也都加了残差连接(Residual Connection)和层归一化(Layer Normalisation)。解码器中对self-attention子层进行了修改,以防止引入当前时刻的后续时刻输入,这种屏蔽与输出嵌入偏移一个位置的事实相结合,确保了位置i的预测仅依赖于小于i的位置处的已知输出。
Transformer出现后,开始取代RNN(循环神经网络)和 CNN(卷积神经网络)成为最热门的信息提取工具,以前做NLP(自然语言处理)研究的喜欢用RNN,做CV(计算机视觉)研究的喜欢用CNN,现在大家都用Transformer了,很多研究进展可以同步到另一个领域。
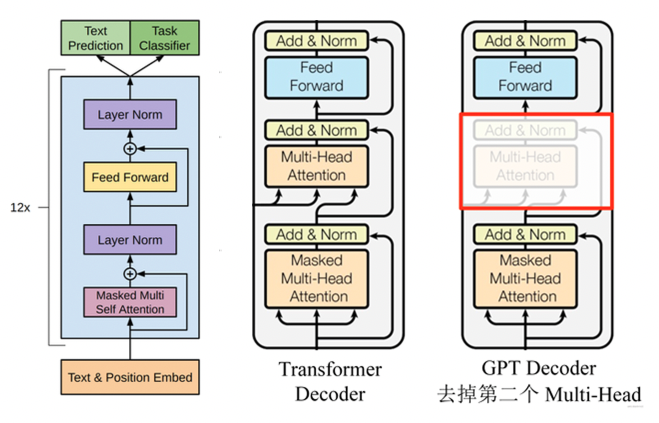
3.4 GPT
传统的NLP模型往往使用大量的数据对有监督的模型进行任务相关的模型训练,但是高质量的标注数据往往很难获得,而且不同任务的模型很难泛化到其他任务上,所以OpenAI在《Imporoving Language Understanding By Generative Pre-training》提出先在大量的无标签数据上训练一个语言模型,然后再在下游具体任务的有标签数据集上进行fine-tune。
GPT是典型的预训练+微调的两阶段模型。预训练阶段就是用海量的文本数据通过无监督学习的方式来获取语言学知识,而微调就是用下游任务的训练数据来获得特定任务的模型。
举一个例子来形容预训练和微调的关系,我们从幼儿园到高中就像预训练过程,不断学习知识,这些知识包罗万象包括语数英物化生等等,最重要的特征就是预训练模型具有很好的通用性;然后读大学的时候需要确定一个专业方向作为未来的职业,所以就会去重点学习专业知识,从而让我们成为更加适合某个专业方向的人才,最重要的特征就是具有极强的专业性

{kind=link}
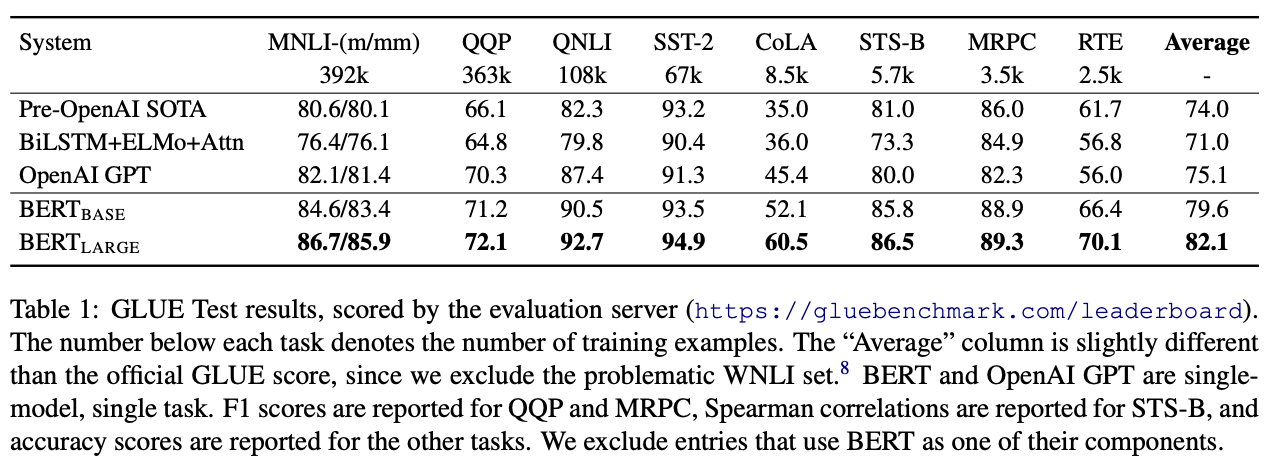
GPT模型效果还是非常出色的,12个任务数据集中9个达到了最好效果。
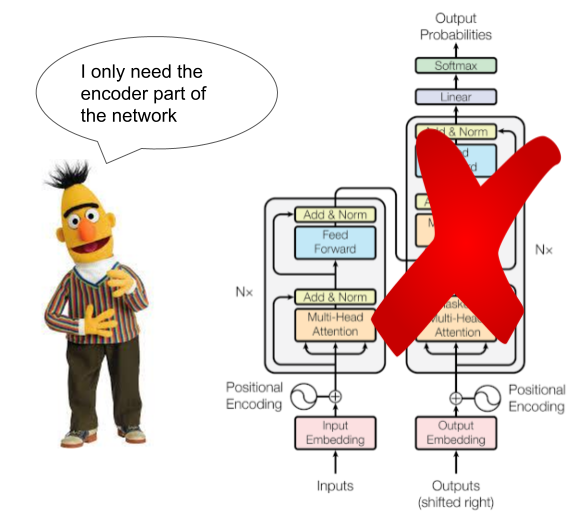
3.5 BERT
2018年10月,Google发表《BERT_Pre-training of Deep Bidirectional Transformers for Language Understanding》,提出了类似于GPT的预训练模型BERT

{kind=link}
BERT和GPT采用了不同的技术路线,简单理解,BERT是一个双向模型,可以联系上下文进行分析,更擅长完形填空;而GPT是一个单项模型,只能从左到右进行阅读,更擅长写作文。
发布更早的GPT-1输给了晚4个月发布的BERT,而且是完败。在当时的竞赛排行榜上,阅读理解领域已经被BERT屠榜了。此后,BERT也成为了NLP领域最常用的模型。

{kind=link}
3.6 GPT-2 & GPT-3
OpenAI既没有认输,也非常头铁。虽然GPT-1效果不如BERT,但OpenAI没有改变策略,而是坚持走大模型路线。接下来的两年(2019、2020年),在几乎没有改变模型架构的基础上,OpenAI 陆续推出参数更大的迭代版本GPT-2、GPT-3,前者有15亿参数,后者有1750亿参数,最终GPT-3的模型效果震惊世人,成功出圈。
GPT-1
2018 年 6 月
12
768
768
1.17 亿
约5GB
GPT-2
2019 年 2 月
48
-
1600
15 亿
40GB
GPT-3
2020 年 5 月
96
96
12888
1750 亿
45TB
但是单纯的说用一个更大的模型打败了对手感觉还不够,GPT-2和3开始卷另一个方向,不用做梯度更新和微调依然可以完成很多任务,也就是Zero-shot。在OpenAI眼中,未来的通用人工智能应该长这个样子:有一个任务无关的超大型的语言模型(Large Language Model, LLM),用来从海量数据中学习各种知识,这个LLM以生成一切的方式,来解决各种各样的实际问题,而且它应该能听懂人类的命令,以便于人类使用

Zero-shot, one-shot and few-shot, contrasted with traditional fine-tuning.
{kind=link}
本身在这么大的模型上做梯度更新和微调就是一个门槛很高的事情,GPT-3模型对于Zero-shot、one-shot和few-shot的支持,使得基于他可以衍生出了上百个基于GPT-3的应用。
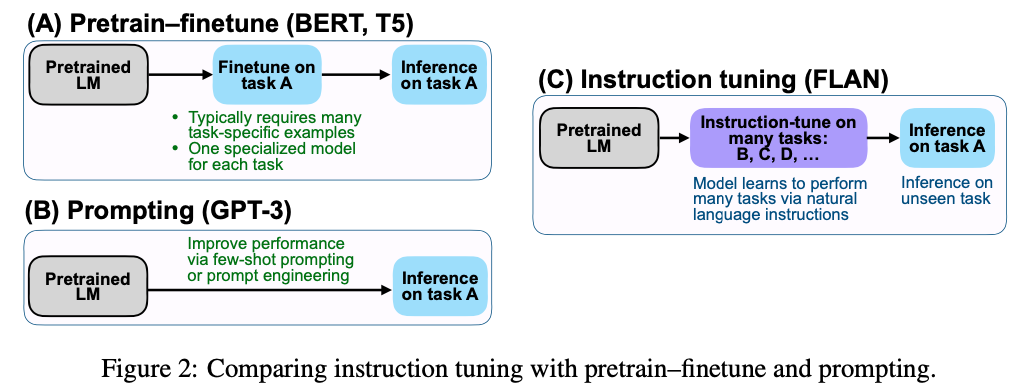
3.7 instruction Tuning
Google在2021年发表《Finetuned Language Models are Zero-Shot Learners》,提出了一种提高语言模型Zero-shot能力的方法。
比如我们要进行一句话的情感分析,“带女朋友去了一家餐厅,她吃的很开心”,我们可以有两种做法:
利用模型补全的能力,改造prompt:“带女朋友去了一家餐厅,她吃的很开心,这家餐厅太__了!”
直接告诉模型任务:“判断这句话的情感:带女朋友去了一家餐厅,她吃的很开心。选项:A=好,B=一般,C=差” instruction Tuning是第二种

pretrain–finetune and prompting and instruction Tuning
{kind=link}
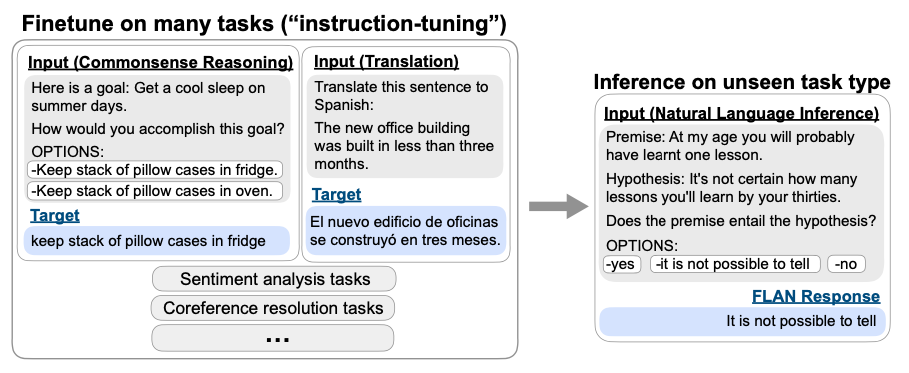
Instruction tuning的动机是为了提高语言模型对instructions的理解和响应能力。其想法是,通过监督来教语言模型执行instructions描述的任务,从而使它将学习到如何遵循instructions,当面对unseen的任务时,模型自然而然地就会遵循instruction做出响应。

{kind=link}
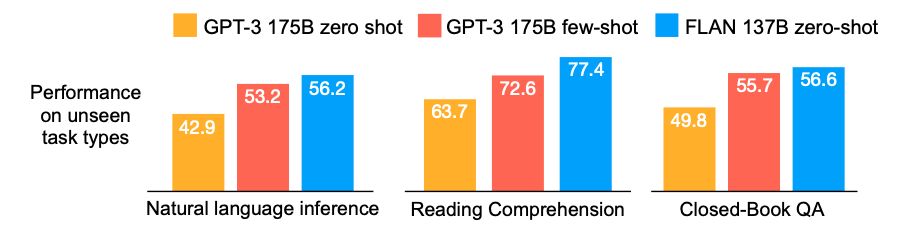
首先在包括commonsense reasoning、machine translation、sentiment analysis等NLP task上进行微调,然后在从未见过的natural language inference任务上进行zero-shot evaluatio

{kind=link}
3.8 InstructGPT/ChatGPT
InstructGPT论文《Training language models to follow instructions with human feedback》,我们已经讲清楚language models和instructions,剩下就是with human feedback。
人工反馈的强化学习(Reinforcement Learning from Human Feedback,RLHF)参考了OpenAI前面的两个工作。
Ziegler在2019年的《Fine-Tuning Language Models from Human Preferences》

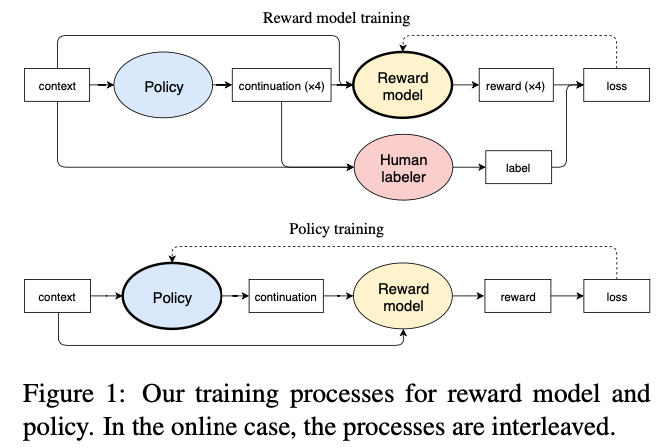{kind=link}
Stiennon在2020年《Learning to summarize from human feedback》

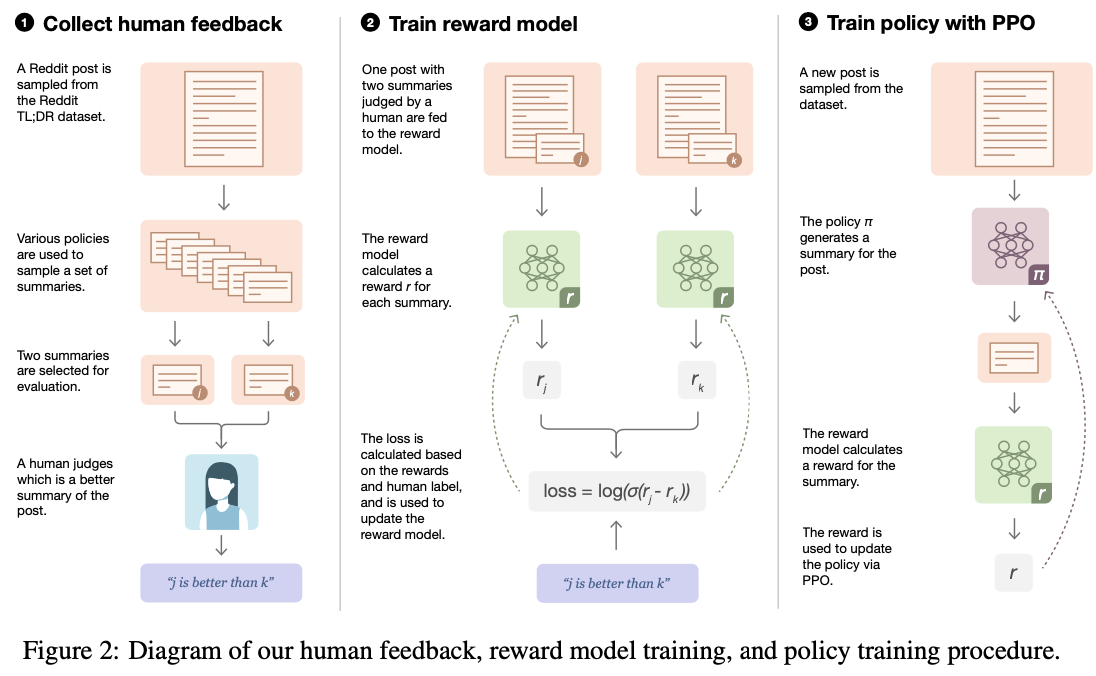{kind=link}
ChatGPT和InstructGPT在模型结构,训练方式上都完全一致,即都使用了指示学习(Instruction Learning)和人工反馈的强化学习(Reinforcement Learning from Human Feedback,RLHF)来指导模型的训练,它们不同的仅仅是采集数据的方式上有所差异。
写在最后
4.1 安全性
2016年,微软AI Tay,种族歧视,下线。 Microsoft shuts down AI chatbot after it turned into a Nazi。 https://www.cbsnews.com/news/microsoft-shuts-down-ai-chatbot-after-it-turned-into-racist-nazi/
2021年,Facebook,AI将黑人标上了灵长目的标签 Facebook Apologizes After A.I. Puts ‘Primates’ Label on Video of Black Men Facebook called it “an unacceptable error.” The company has struggled with other issues related to race. https://www.nytimes.com/2021/09/03/technology/facebook-ai-race-primates.html
语言模型的输出特别灵活,导致出错的概率会更大,OpenAI作为一个创业公司,媒体对于GPT的容忍度大一些,如果是大公司做的GPT模型,可能已经下架了。
4.2 成本

{kind=link}
大模型背后离不开大数据、大算力。GPT-2用于训练的数据取自于Reddit上高赞的文章,数据集共有约800万篇文章,累计体积约40G;GPT-3模型的神经网络是在超过45TB的文本上进行训练的,数据相当于整个维基百科英文版的160倍。
在算力方面,GPT-3.5在微软Azure AI超算基础设施(由V100GPU组成的高带宽集群)上进行训练,总算力消耗约3640PF-days(即每秒一千万亿次计算,运行3640天)。可以说,大模型的训练就是靠烧钱烧出来的。据估算,OpenAI的模型训练成本高达1200万美元,GPT-3的单次训练成本高达460万美元。
根据《财富》杂志报道的数据,2022年OpenAI的收入为3000万美元的收入,但净亏损总额预计为5.445亿美元。阿尔特曼在Twitter上回答马斯克的问题时表示,在用户与ChatGPT的每次交互中OpenAI花费的计算成本为“个位数美分”,随着ChatGPT变得流行,每月的计算成本可能达到数百万美元。
大模型高昂的训练成本让普通创业公司难以为继,因此参与者基本都是的科技巨头。
Last updated